Dataflows are a wonderful way to populate data within Dataverse tables. Dataverse is a cloud-based data service platform by Microsoft that is meant to consolidate and host the various data used within the Power Platform suite of products. The data is hosted within tables, both standard, and custom. During migration to a new environment, the structure is migrated, but the table remains empty of data. Dataflows can assist with populating the correct data into the environment.
Getting started with dataflows
Dataflows can be a bit tricky when first trying to set up a query to migrate any type of data.
First, we want to go into the Power Apps environment. On the left-hand menu, there is a drop-down for Dataverse. Once selected, the menu will expand to include Tables, Choices, Dataflows, and others. The Tables field will show all the data within a given environment. Choices show the different custom datatypes users have created within an environment.
What happens when the data that you need is not within the environment? That is where Dataflows come into play.
Dataflows can grab data from external sources and bring them into the environment to be used within solutions and Power Apps (both canvas and model-driven). When creating a new dataflow, you will be able to select + Start from blank or Import template. For this example, we will + Start from blank. Once you have named your dataflow, there will be an additional checkbox for Analytical Entities only. This example will not select that checkbox. More information on this can be found below the main article.
Once selected, you are then able to select a data source. For those that have worked with Power BI or Power Query in Excel in the past, this will look very familiar. You will be able to choose from a variety of sources, some examples include other dataflows, Excel, Dataverse, and SharePoint lists. For all selections, you will be prompted for a link to the source along with some connection credentials. Once those are provided, you will see the data available from that source. The left menu will have a drop-down with all the available types of data; for Excel, the data can come in pre-formatted as a table or a sheet. Once the data format is selected, the Transform data in the lower right-hand corner should be selectable. Each selected data will populate as a different query.
Now we have our data in the Power Query Online editor within Dataverse. The functionalities to transform data are available just as they would be in Power Query. You can transform data by splitting columns, transposing tables, pivoting, and unpivoting columns just as you would for a typical PQO transformation. Similarly, conditional columns and custom columns are available.
Once the data is transformed the way you want it, if loading onto an existing Dataverse table we highly recommend renaming the columns to match the Dataverse logical name, please select Next. On the next screen, we can select the load settings. There are three load options: Load to a new table, Load to an existing table, or Do not load.
Load to a new table will create the table in Dataverse. A unique primary name column will be auto-generated if a specific column is not selected. The unique primary name column will be used as a key in future queries or uses of the table. Alternate keys can also be selected, but the data type for the alternate keys must be Text.
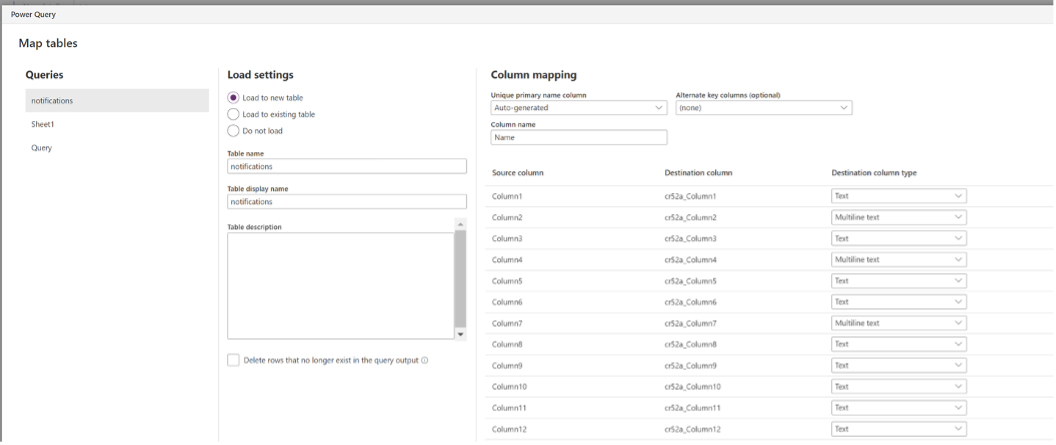
Load to a new table
Load to an existing table will enable the query to append to an existing Dataverse table. Delete rows that no longer exist in the query output can be enabled when a key is available to query against. Keys are extremely helpful when it comes to upserting information and preventing duplication. Auto map is also available for query columns that are syntactically the same as the destination column. Lookup columns and choice columns for loading to an existing column can be tricky. Lookup columns are available when there are alternative keys in the referenced table. When the alternate key is configured, the column will show as columnName.tableName_columnName and will be writable as a text field. Choice columns require the integer that was predetermined. When a choice column was created, each choice is assigned a value. The table expects the query to load the value rather than the formatted name value. The integer value can be found by going to the choice field definition and expanding the view more options.
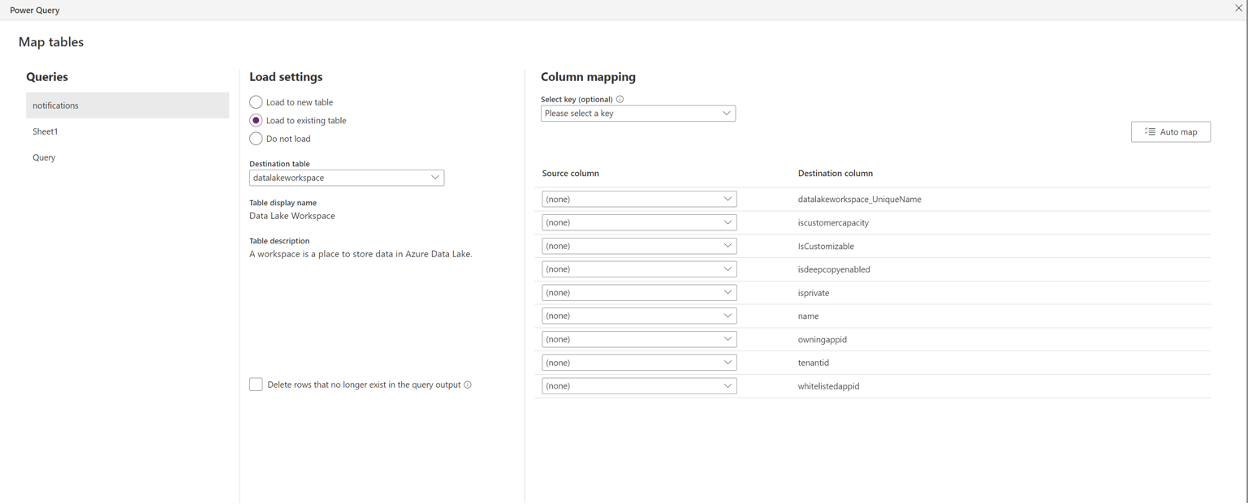
Load to an existing table
Do not load is as simple as it sounds. This option is available when a query is imported specifically to feed into other queries and where you do not want to load the data into any Dataverse tables. This is useful when queries are loaded into the editor for merges, appends, or extracting variables for other queries.
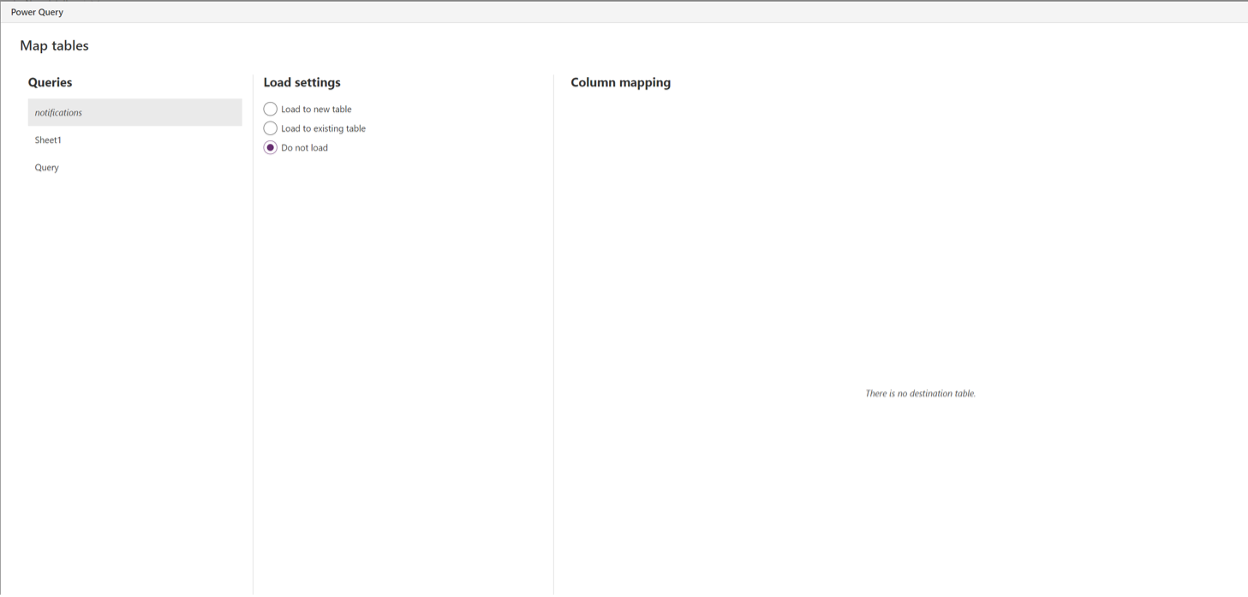
Do not load
Once the columns are mapped, the Next button should be available in the lower right-hand corner. Here we can select the refresh settings. The two options available are Refresh manually and Refresh automatically. Both options have a checkbox to enable failure notifications to the dataflow owner. Refreshing automatically enables a scheduled refresh to occur at the frequency of your choosing. From there, the Publish option should be selectable. When dataflows are published, an auto refresh is generated to then load data into the table. If you decide to come back to the dataflow to edit the queries, the publish button will be available after the columns have been mapped.
What happens when your destination column does not appear in column mapping?
This scenario typically occurs for lookup columns. Lookup columns reference another table B from table A. Create alternative keys on Table B that is a text column. Reset the load settings on the column mapping step and the destination column should appear
What are Analytical Entities?
Analytical entities are meant to specifically analyze customer insights with full integration into AI features. This selection allows you to map to a specific entity (also called a table) within Dataverse to track the usage and patterns from that table. It also enables computed entity to process substantial amounts of data that tracks the flow of data from one table within the environment to another. This aids in the performance of data transformations since it stores the output of a transformation to be potentially used by multiple tables. The default for these types of flows is a full load rather than incremental – this setting can be changed by manually setting up incremental load in the dataflow settings.
Inserting data into a Dataverse table
Dataverse tables should be pre-populated with data before use but depending on the use case the best option to do so may differ.
Option 1: Business Rules
Use Cases:
- Working with a single table in Dataverse with a default value
- Set and clear column values
- Show or hide columns in a Power Apps app
- Validate data and display error messages
- Set default values for columns
Limitations:
- Limited to just a single table at a time when consolidating rules in Dataverse
- Does not reference multiple tables for rules but can use the same logic across multiple tables
- The scope is limited to data entry via forms
- Basic logic can be implemented. Logic is limited to if-else statements at this time. It is remarkably like a conditional column in PQO or PBI
- They aren’t executed inside Dataverse.
- The warning and error messages live inside the rule and table rather than external triggers
- Must be created inside a solution
Bonus features:
- Can apply logic and validations without writing code; it has a quite simple interface for fast-changing and commonly used rules.
- Rules can be implemented across multiple tables
- Can be set at each entry to trigger an action in Power Automate or within a Power Apps canvas or model-driven app if the table is used and defined within an app
Option 2: Dataflows
Use cases:
- Inserting copious amounts of data from various sources into a Dataverse table
- Creating custom values on a row-based level through custom columns or conditional columns for large sets of data
- Upserting information to large amounts of data through keyed values
- Long-term maintenance is available for substantial amounts of data through scheduling options
Limitations:
- The scope is limited to columns applied to rows rather than entity based. Will need to create calculated columns using formulas rather than manually setting each row
- Only one owner is currently enabled. If another user wanted to modify the dataflow, then they would have to initiate a takeover
- Migrating the dataflow to another solution requires an update to each query’s connection
- It does not default to validate existing data but will append the data from the query into the Dataverse table, keys will need to be used to upsert or modify existing data.
Bonus features:
- Able to be created outside of a solution
- Utilizes Power Query as a backend, highly versatile for transformation and large datasets
- Publishing a dataset will automatically trigger a new refresh
- Automapping is available when the query’s final columns match the destination columns’ syntax
Challenges:
- Lookup columns need alternative keys for each table to write to the destination lookup column
- Choice columns need to be unpivoted before writing to attribute and value separately
- User Experience is not friendly if you are unfamiliar with Power Query (contrastingly: if you are familiar with Power Query this would be the most intuitive of the options)
Option 3: Power Automate
A very powerful tool that can update tables through row entities.
Use cases:
- Upserting a row in a Dataverse table
- Migrating a dataset (<5k rows) into a Dataverse table from a singular external source
- Clearing a Dataverse table
- Updating multiple tables from multiple sources using parallel branches
Limitations:
- Does not typically do well with large datasets (>5k rows)
- This can be overcome through pagination and logic
- Lookups and references to other tables need specific syntax to write to the field
- /Entityset(‘value’)
- Choice fields intake an integer that was automatically assigned when the choice field was generated
- The number values can be seen by going to the Choice field definition and expanding the View More option.
- Will need the row id from the Dataverse table to update the fields
- Can be overcome with the list rows function to grab row ids
New to Dataflows, Dataverse, and the Power Platform?
Reach out at any time to discuss Compass365’s Power Platform Consulting Services. We are happy to help. Please contact us or reach out directly to Cathy Ashbaugh, cashbaugh@compass365.com to arrange for a complimentary consultation.
Compass365, a Microsoft Gold Partner, delivers SharePoint, Microsoft Teams, and Power Platform solutions that help IT and Business leaders improve how their organizations operate and how their employees work.